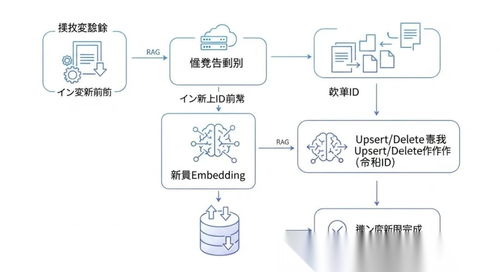
在上一部分中,我们探讨了阿里内部海量数据处理系统的需求、挑战以及核心技术组件。本部分将深入分析其整体架构设计、数据服务创新,以及阿里如何通过自研和开源技术推动数据处理服务的发展。
一、整体架构设计
阿里内部海量数据处理系统采用了分层架构,以确保高扩展性、可靠性和效率。主要分层包括:
- 数据采集层:通过DataX、Logtail等工具实现多源异构数据的实时和批量采集,支持日志、数据库、流数据等。
- 存储层:基于分布式存储系统如HDFS、阿里云OSS,结合自研的盘古和表格存储(OTS),提供高吞吐和低延迟的存储能力。
- 计算层:整合批处理和流计算,使用MaxCompute(原ODPS)处理离线数据,Flink和Blink支持实时流处理,确保数据处理的灵活性和实时性。
- 服务层:通过DataWorks、AnalyticDB等平台,提供数据开发、管理和分析服务,支持用户快速构建数据应用。
这种分层架构实现了数据处理的高内聚和低耦合,便于模块化扩展和维护。例如,在双11等大促场景中,系统通过弹性伸缩和资源调度(如Fuxi调度器)应对峰值负载,确保服务稳定性。
二、数据处理服务的创新
阿里在数据处理服务上的创新主要体现在以下几个方面:
- 统一数据服务平台:通过OneData方法论,实现了数据标准化和资产化管理,减少了数据冗余和重复计算。阿里内部产品如淘宝、支付宝等共享统一的数据服务,提升了数据一致性和复用率。
- 实时与离线一体化:借助Flink和MaxCompute的融合,阿里构建了流批一体的数据处理引擎。例如,在推荐系统中,实时用户行为数据与离线模型数据结合,实现动态优化,提升了用户体验。
- 智能化数据治理:引入AI技术进行数据质量监控和自动优化,例如通过机器学习检测数据异常,自动修复数据问题,降低了人工干预成本。
- 开源与自研结合:阿里积极开源内部技术,如Flink、Druid等,同时自研了盘古、Fuxi等核心组件,形成了生态闭环。这不仅推动了行业进步,也反哺了内部系统的优化。
- 云原生数据处理:随着阿里云的发展,数据处理服务逐步迁移到云原生架构,利用容器化和Serverless技术,实现资源的按需分配和成本优化。
三、案例:从淘宝到全场景应用
以淘宝为例,数据处理系统每天处理PB级数据,支撑搜索、推荐、风控等核心业务。通过架构创新,淘宝实现了:
- 实时用户画像更新,毫秒级响应推荐请求。
- 离线数据挖掘,助力商家进行销售预测和库存管理。
- 数据服务API化,让业务方快速调用数据,缩短开发周期。
阿里将这一架构推广到金融、物流等场景,形成了通用的数据处理解决方案,体现了其可复制性和适应性。
四、总结与展望
阿里的海量数据处理系统设计,不仅解决了内部业务的高并发和数据多样性挑战,还通过架构优化和服务创新,为行业树立了标杆。随着5G和物联网的普及,数据处理将面临更大规模和实时性要求。阿里正探索边缘计算、联邦学习等新技术,以构建更智能、高效的数据处理生态。
从阿里内部产品可以看出,海量数据处理系统的成功关键在于:分层架构的灵活性、实时与离线的融合、智能化治理,以及开源与自研的协同。这些经验为其他企业提供了宝贵参考,推动数据处理技术不断向前发展。